3D Reconstruction & Generation
Reconstructing and generating complete, physically plausible 3D structure from unposed views.
Hi! I am a third-year PhD student at TU Munich and University of Oxford through ELLIS, advised by Daniel Cremers and Andrea Vedaldi. I also work closely with Chuanxia Zheng and Nikita Araslanov. During my PhD, I was a student researcher at Google Zurich hosted by Keisuke Tateno and Federico Tombari.
Previously, I received my Master's degree in Computer Science from ETH Zurich, advised by Marc Pollefeys. I worked on 3D vision projects at Microsoft Spatial AI Lab Zurich, Computer Vision and Geometry Group (CVG), and Computer Vision Lab (CVL). Before this, I obtained my Bachelor's degree in Computer Science from The Chinese University of Hong Kong and interned at SenseTime Research.
I build 3D-native systems that perceive, reconstruct, and generate dynamic worlds — the spatial foundation for world models and agents to simulate, predict, and act across space and time.
Reconstructing and generating complete, physically plausible 3D structure from unposed views.
Learning 4D representations and scene motion to capture how dynamic worlds evolve over time.
Localization, tracking, and motion estimation that ground agents and world models in space and time.

International Conference on Machine Learning (ICML), 2026
Preprint / Project Page (under construction)
A token-based framework that fuses partial point-cloud sequences over time into complete, temporally coherent 4D geometry.

International Conference on Learning Representations (ICLR), 2026
arXiv / Paper / Project Page / Code
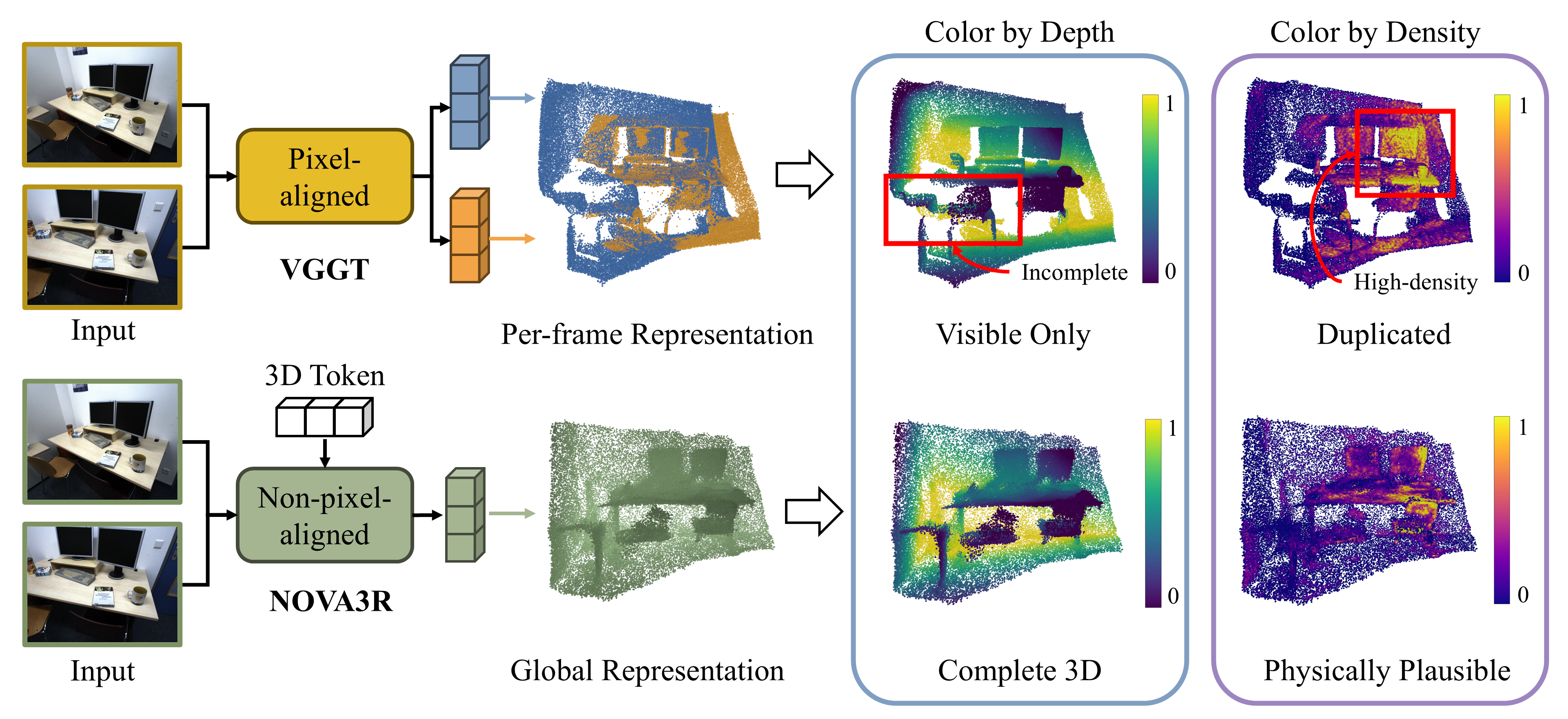
A feed-forward transformer that builds a global latent representation to generate complete, amodal 3D structure from a set of unposed images.

International Conference on Computer Vision (ICCV), 2025 (Oral, Best Paper Candidate)
arXiv / Paper / Project Page / Code
A method for consistent dynamic scene reconstruction via motion decoupling, bundle adjustment, and global refinement.
German Conference on Pattern Recognition (GCPR), 2025 (Oral, Best Paper Award)
arXiv / Project Page / Code
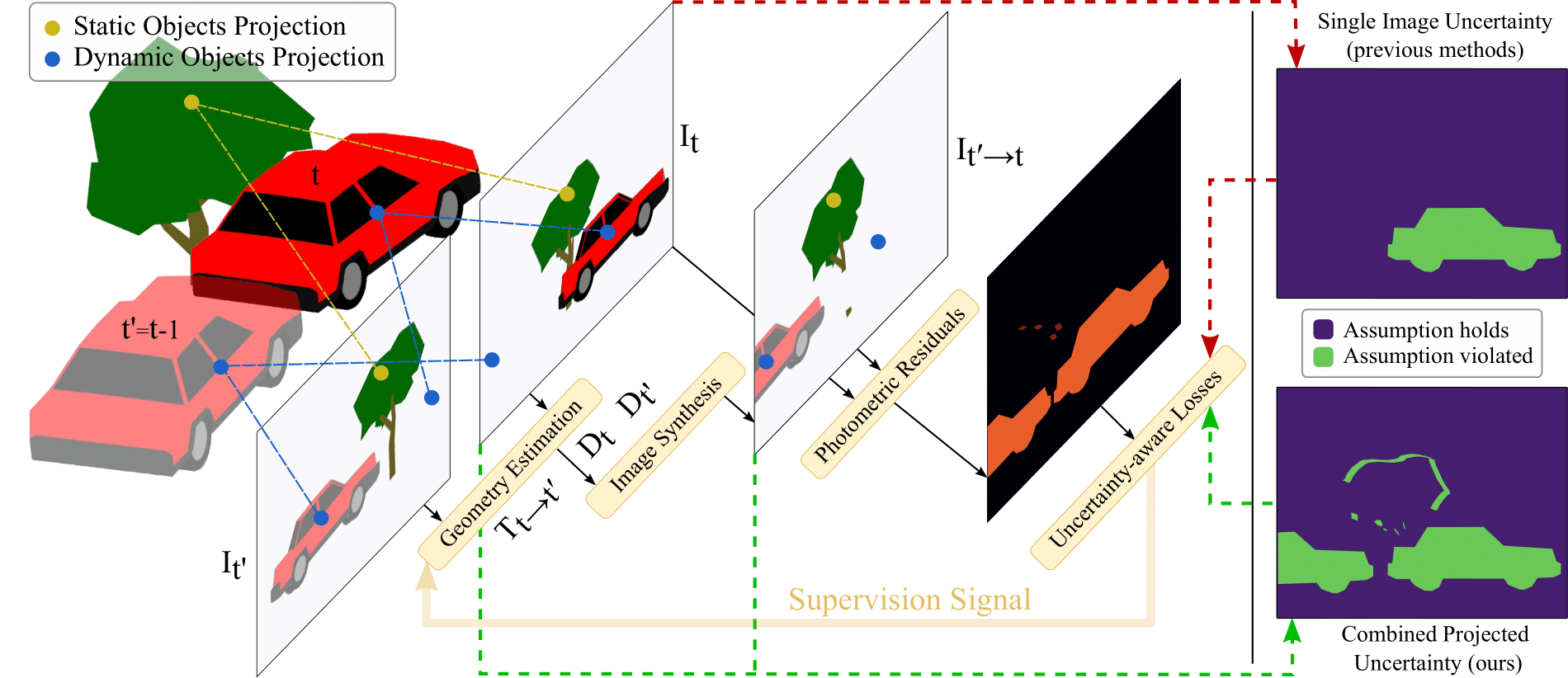
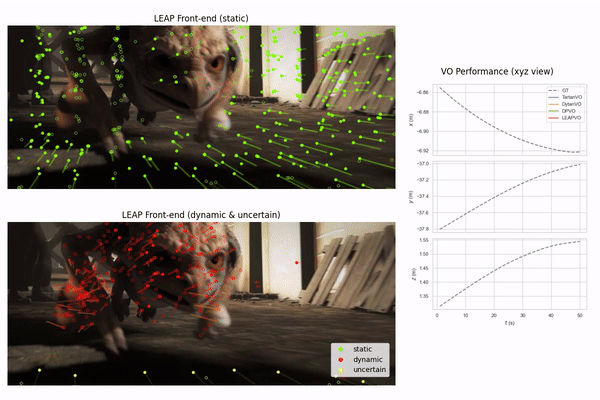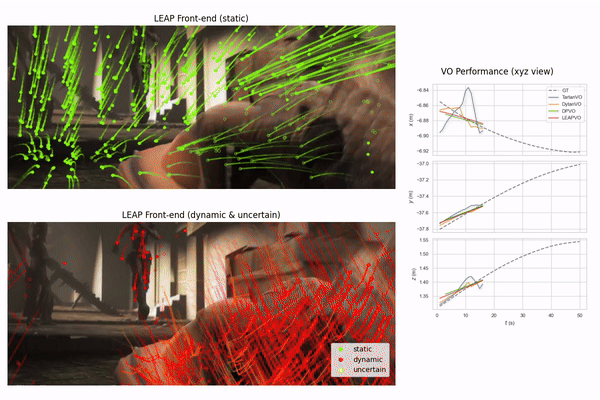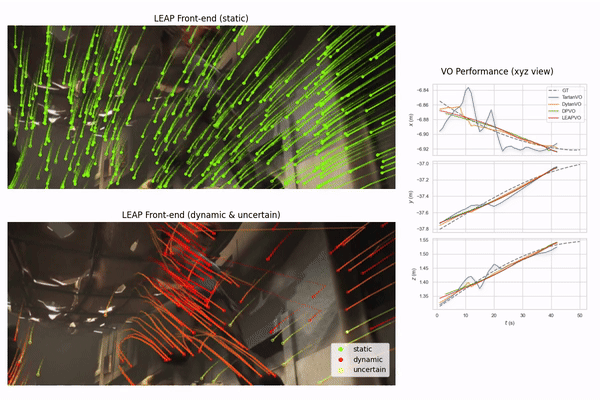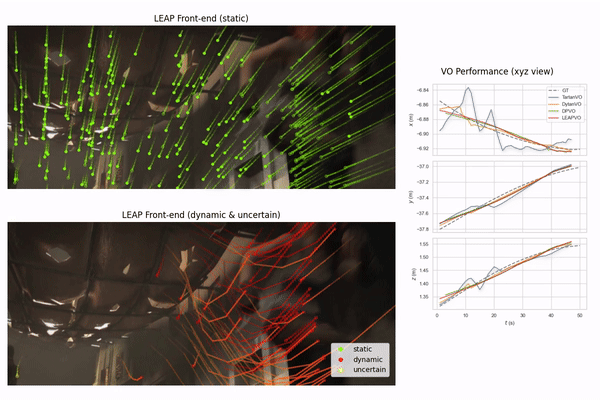
An unsupervised visual odometry method that improves pose estimation in dynamic scenes.

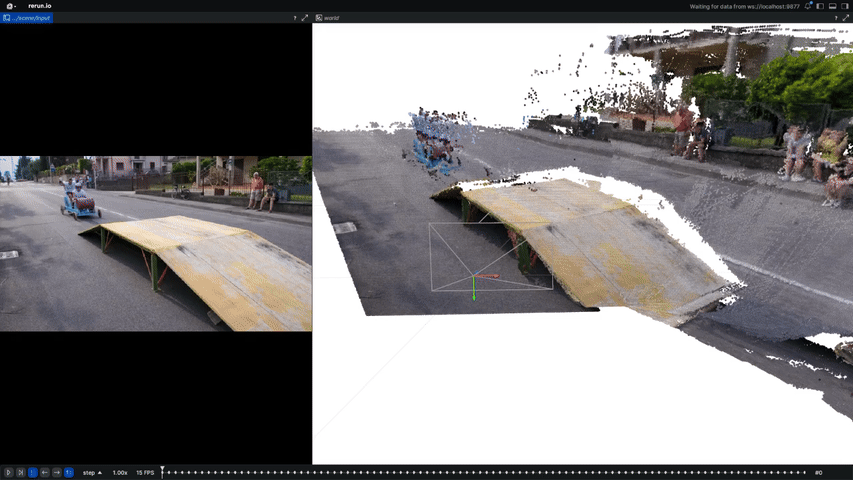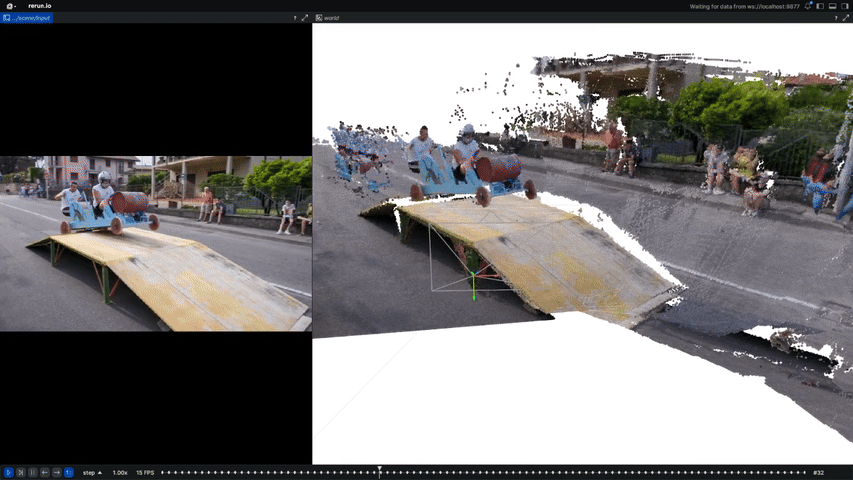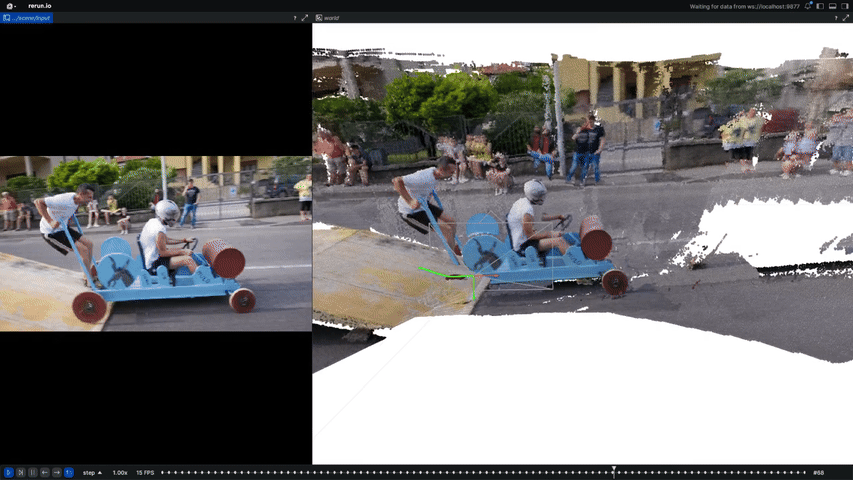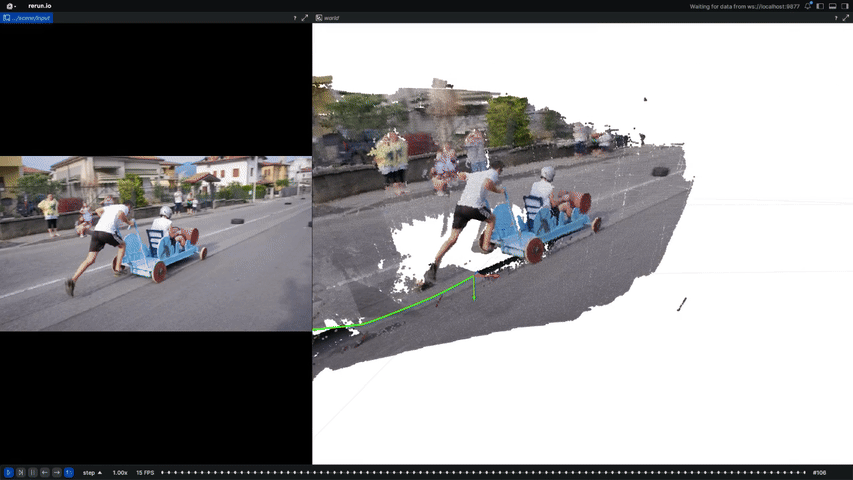
Computer Vision and Pattern Recognition Conference (CVPR), 2025
arXiv / Paper / Project Page / Code
A method for learning camera poses and intrinsics from dynamic casual videos.


IEEE Transactions on Image Processing (TIP), 2026
Dynamic radiance field reconstruction from only two images, enabled by object-level bundle adjustment.
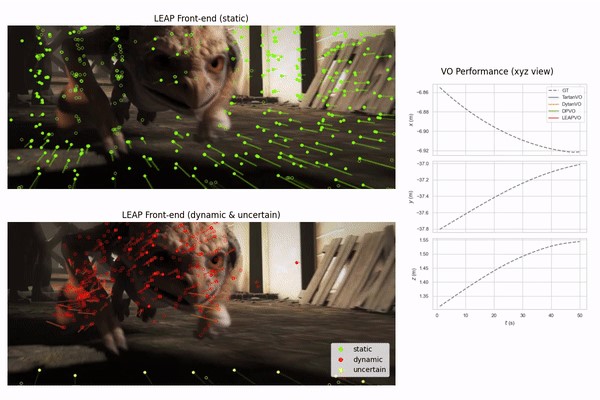
Computer Vision and Pattern Recognition Conference (CVPR), 2024
arXiv / Project Page / Code / Video
A robust visual odometry system leveraging temporal context with long-term point tracking to tackle occlusions and dynamic environments.

International Conference on Robotics and Automation (ICRA), 2024
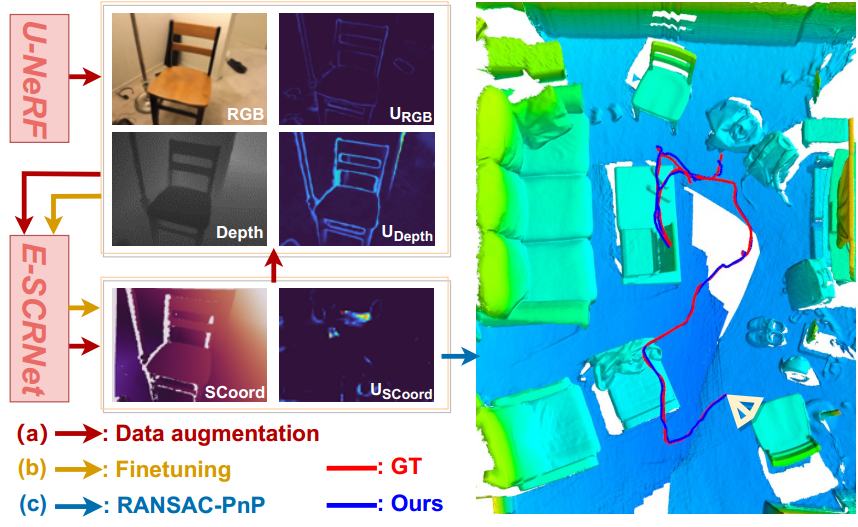
A visual localization pipeline using rendered data from NeRF, uncertainty-guided novel view selection, and evidential scene coordinate regression.
International Conference on Intelligent Robots and Systems (IROS), 2023
IEEE Robotics and Automation Letters (RA-L), 2023
arXiv / Project Page / Video
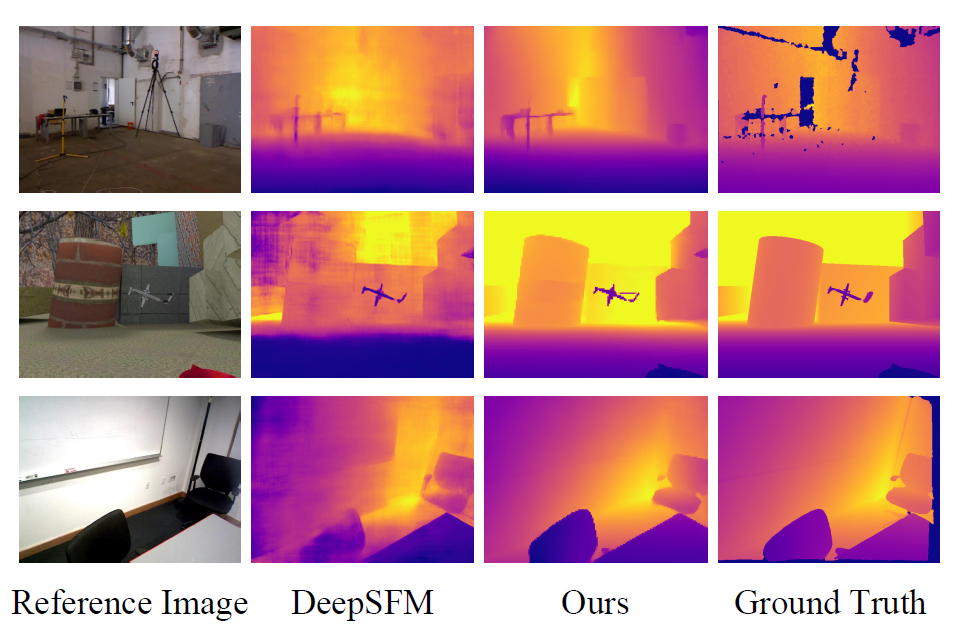
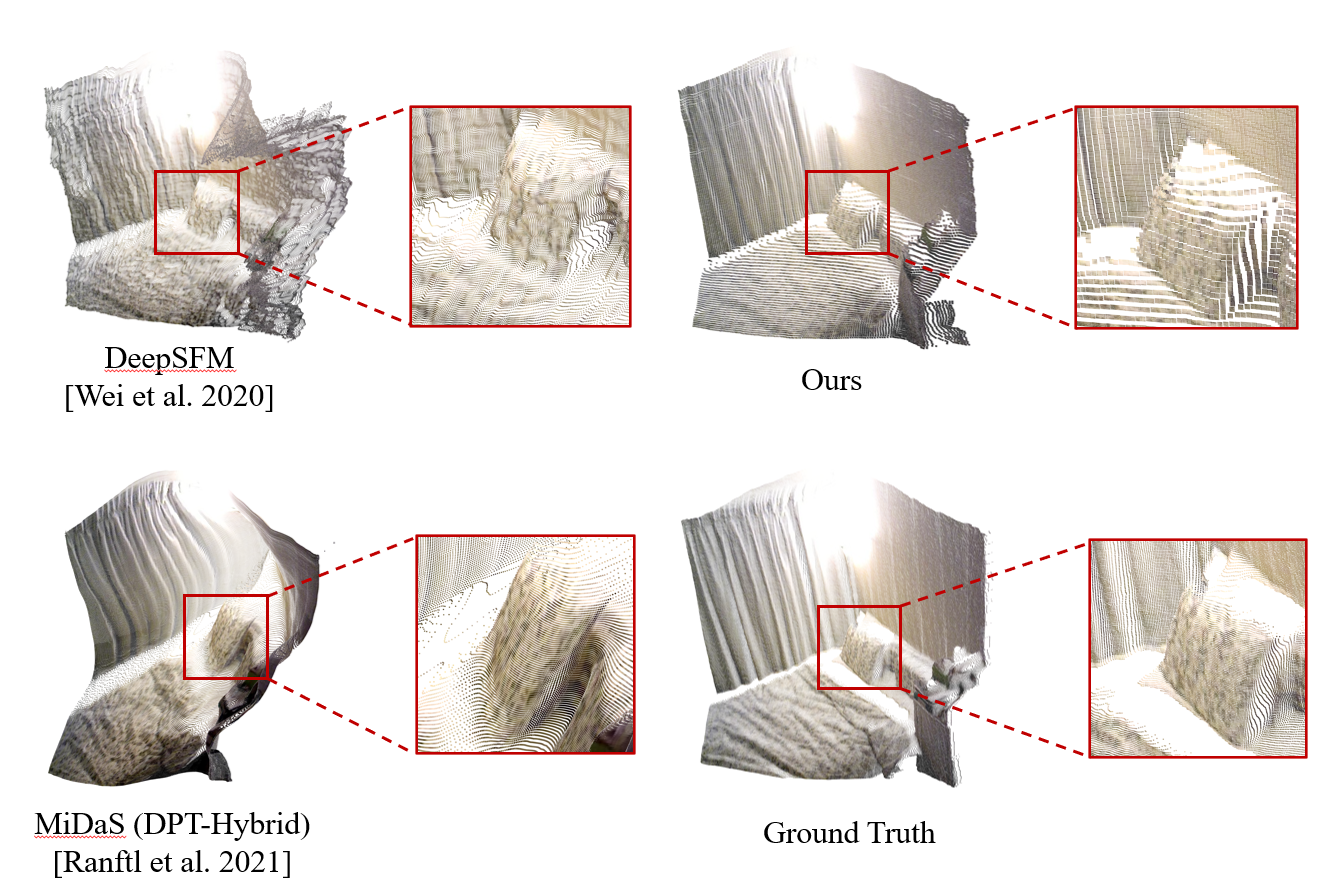
An accurate and reliable pipeline for dense two-view SfM using weighted bundle adjustment with robust outlier filtering and learning-based confidence modeling.

ACM International Conference on Multimedia (ACM MM), 2020 (Oral)
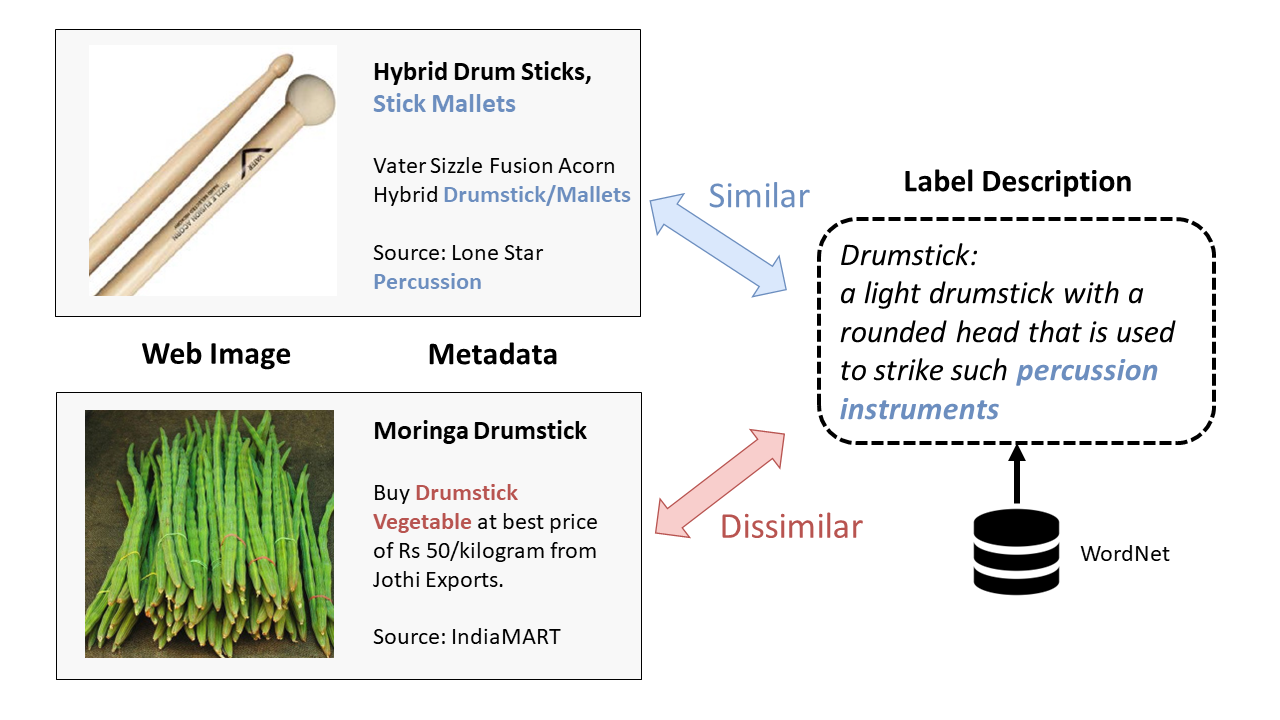
Webly supervised learning for semantic label confusion using visual-semantic graph with metadata-aware anchor selection and GNN-based label propagation.

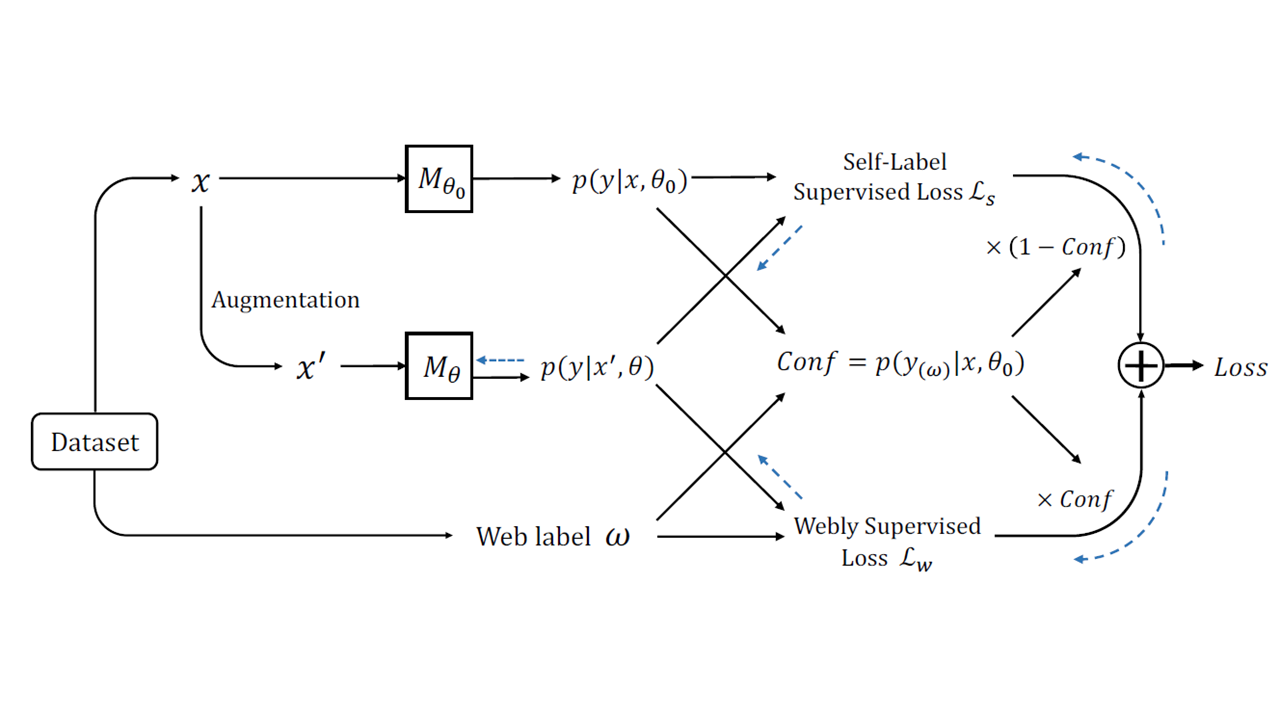
European Conference on Computer Vision (ECCV), 2020
Webly supervised learning for noisy label classification via sample-wise web label correction with model confidence and pseudo machine label.


Supervised by Paul-Edouard Sarlin and Marc Pollefeys
Demo (KITTI) / Demo (Zurich) / Report
A robust and highly-extensible Python SLAM built on pycolmap; achieved better pose accuracy and significant speed improvement compared to COLMAP.
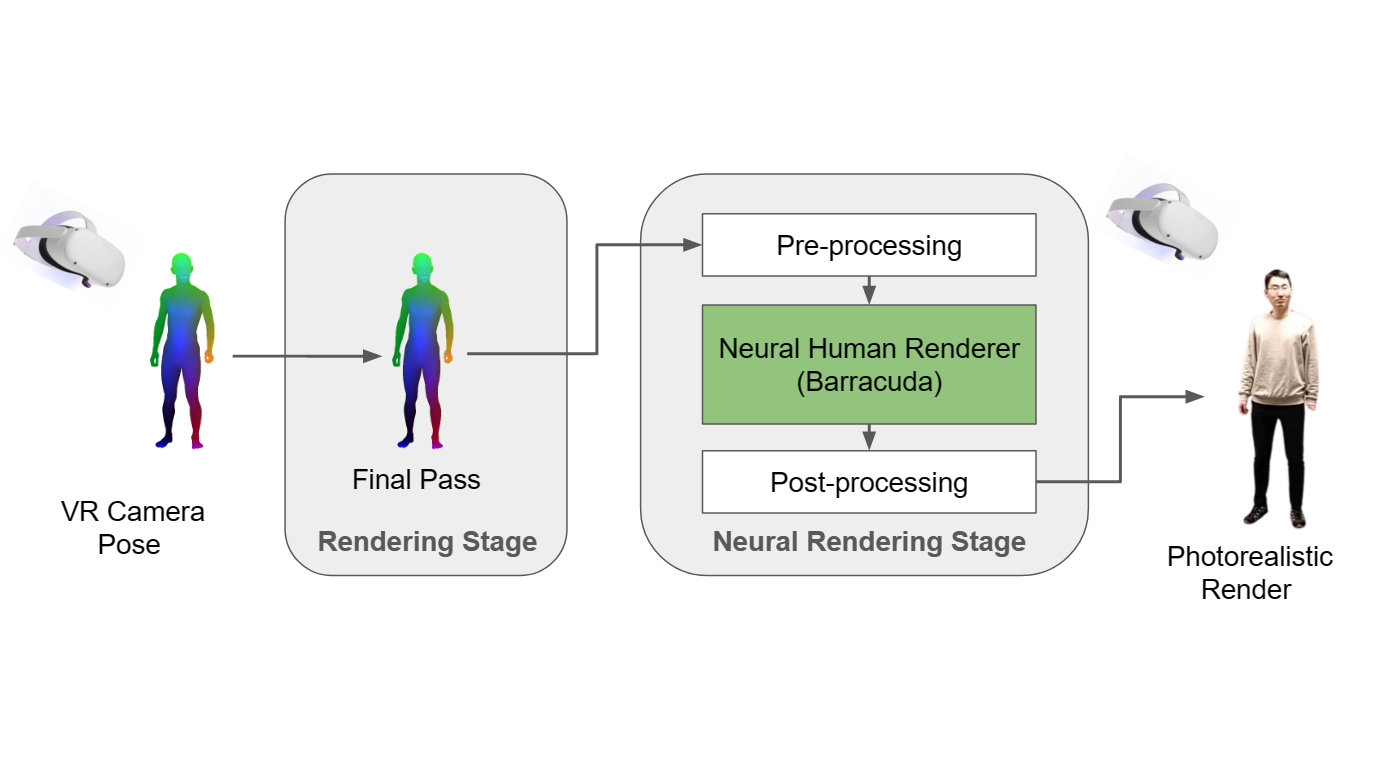
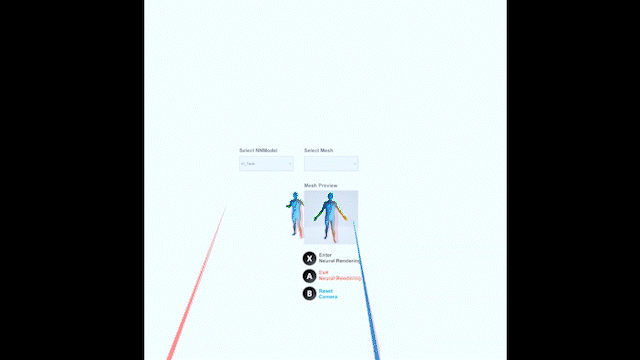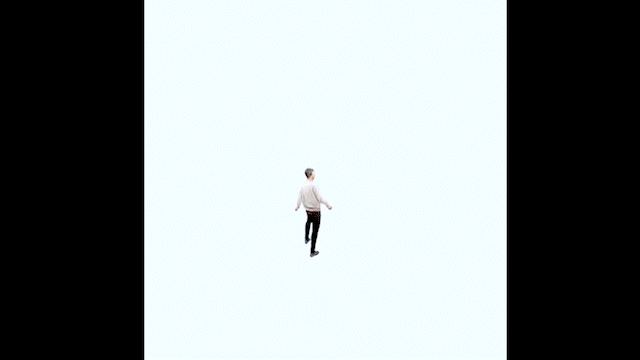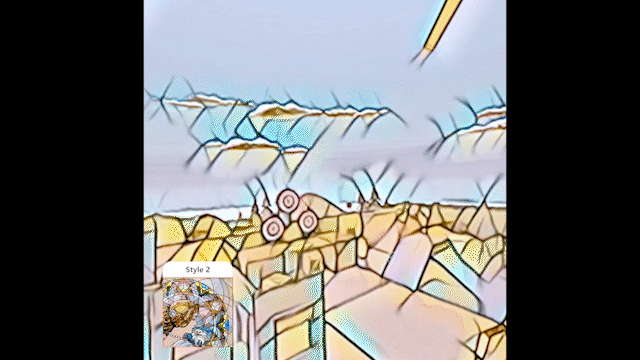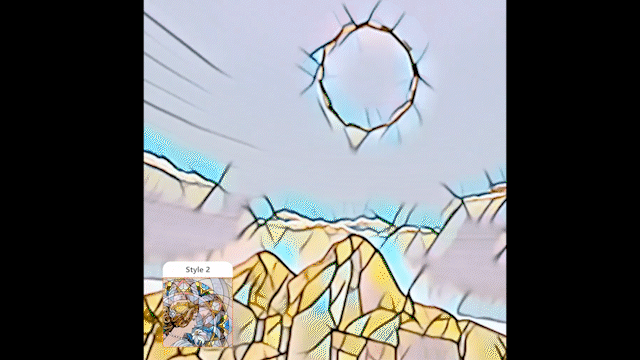
Supervised by Sergey Prokudin
A general neural rendering pipeline for photorealistic synthesis in VR devices in real-time; demo included human neural rendering and scene style transfer.

Mentors: Keisuke Tateno, Federico Tombari

Mentors: Litong Feng, Wayne Zhang
 NOVA3R: From Pixel-Aligned Reconstruction to Non-Pixel-Aligned World
NOVA3R: From Pixel-Aligned Reconstruction to Non-Pixel-Aligned World

